|
Grado en Ingeniería Informática
Procesadores de Lenguajes
Curso 2022/2023
|
Práctica 2 |
|
Implementación del analizador léxico del lenguaje Tinto |
|
OBJETIVOS |
- Describir las clases necesarias para desarrollar un
analizador léxico genérico
- Describir la implementación del analizador léxico del lenguaje de
programación Tinto
|
|
CÓDIGO A UTILIZAR |
El código de esta práctica contiene 7 ficheros distribuidos en
dos paquetes. El paquete tinto.parser contiene las clases dedicadas a desarrollar los analizadores léxicos. Este paquete
incluye cuatro clases que permiten desarrollar analizadores léxicos de forma genérica y dos clases que desarrollan el
analizador léxico del lenguaje de programación Tinto como caso particular. El paquete tinto contiene la clase
TintoCompiler que en este caso se limita a comprobar el funcionamiento del analizador léxico.
|
|
ANALIZADOR LÉXICO GENÉRICO |
|
Entre las clases incluidas en el código se encuentran cuatro clases
que permiten la descripción genérica de los analizadores léxicos. A
continuación se describen estas clases.
Esta clase describe un componente léxico. Los atributos de los componentes
léxicos aparecen como campos de la clase: categoría léxica a la que
pertenece (kind), lexema del componente (lexeme), fila en la
que comienza el componente en el fichero de entrada (row) y columna
de comienzo en el fichero de entrada (column). El constructor de la
clase recibe estos valores como argumentos. El resto de los métodos permiten
acceder a estos atributos.
Esta clase describe un error léxico. Para identificar el error se utiliza el
carácter que lo provoca y la fila y columna en la que se encuentra en el
fichero de entrada. Con esta información se crea el mensaje de error
asociado a los errores de tipo léxico.
Esta clase desarrolla un flujo de datos de entrada basado en un doble buffer
que optimiza el acceso a un fichero de caracteres y permite retroceder en la
lectura. El analizador léxico accede al fichero de entrada a través de esta
clase, lo que le permite tanto avanzar como retroceder en el flujo de
caracteres. La clase se encarga también de calcular la fila y la columna a
la que pertenece cada uno de los caracteres almacenados en el buffer en cada
momento. Desde el punto de vista del analizador léxico, la clase ofrece los
siguientes métodos: getNextChar(), para obtener el siguiente carácter
de la cadena de entrada; getRow(), para obtener la fila en la que se
encuentra el último carácter leído; getColumn(), para obtener la
columna en la que se encuentra el último carácter leído; retract(int),
para retroceder un número de caracteres en el flujo de entrada; y close(),
para cerrar el flujo de datos. Internamente la clase dispone de los
siguientes campos: stream, que almacena el flujo de datos del fichero
de entrada; buffer, que almacena los bytes leídos del flujo de
entrada; row, que contiene el número de fila correspondiente a cada
carácter almacenado en el buffer; column, que contiene el número de
columna correspondiente a cada carácter almacenado en el buffer; index,
que contiene la posición del último carácter solicitado por el analizador
léxico; y half, que indica si la última lectura del flujo de entrada
se almaceno en la parte baja del buffer o en la parte alta. El método
interno load() se encarga de leer un bloque de 1024 bytes del flujo
de entrada y almacenarlo en la parte baja o alta del buffer, así como de
actualizar los valores de la fila y la columna correspondiente al bloque
cargado. El método getNextChar(), además de devolver el siguiente
carácter, se encarga de detectar cuando es necesario cargar otro bloque de
datos.
Esta clase abstracta desarrolla un analizador léxico genérico basado en una
máquina discriminadora determinista. Para implementar un analizador léxico
concreto es necesario desarrollar los siguientes métodos abstractos:
transition(int,char), que contiene las transiciones del autómata finito
determinista que describe el analizador léxico; isFinal(int), que
indica cuales son los estados finales del autómata; y getToken(int,
String, int, int), que genera el componente léxico asociado a cada
estado final. El método más importante de la clase es getNextToken(),
que obtiene el siguiente componente léxico del fichero de entrada. Este
método, por su parte, se limita a llamar al método privado tokenize()
hasta obtener un valor distinto de nulo. El método tokenize()
desarrolla el comportamiento de una máquina discriminadora determinista:
parte del estado inicial; realiza todas las transiciones posibles del
autómata hasta alcanzar un estado en el que no existan transiciones para el
carácter correspondiente; retrocede hasta el último estado final alcanzado
en las transiciones devolviendo al flujo de entrada los caracteres leídos en
estas últimas transiciones; y devuelve el componente léxico asociado al
estado final alcanzado y a la lista de caracteres leídos. Cuando el estado
final corresponde a un comentario o a un blanco del lenguaje el método
devuelve el valor nulo. El funcionamiento del método consiste en almacenar
en la variable lexeme los caracteres que han permitido alcanzar un estado
final y en la variable tainting los caracteres leídos desde el último
estado final hasta el estado actual.
|
|
EL ANALIZADOR LÉXICO DE
TINTO |
|
Además de las comentadas anteriormente, la implementación
del analizador léxico del lenguaje de programación Tinto consta de dos
archivos: TokenConstants y TintoLexer. La interfaz
TokenConstants define las constantes asociadas a las diferentes
categorías léxicas del lenguaje Tinto. Por su parte, la clase TintoLexer
extiende la clase Lexer desarrollando el analizador léxico de Tinto.
Para ello desarrolla los métodos transition(int,char), isFinal(int)
y getToken(int,String,int,int) que describen el autómata finito
determinista asociado a la especificación léxica del lenguaje Tinto. A
continuación vamos a describir este autómata.
El lenguaje acepta los comentarios definidos en C, C++
y Java, es decir, el comentario multilínea (que comienza por "/*" y
termina en "*/") y el comentario de una línea (que comienza en "//" y
termina en el salto de línea). Los caracteres blancos son el espacio, el
tabulador y los saltos de línea. En la siguiente imagen se muestra la
parte del AFD que desarrolla los comentarios y blancos. El estado 4
corresponde al estado final de un comentario multilínea. El estado 6
corresponde al estado final de un comentario de una línea. El estado 7 es
el estado final de los blancos. El estado 1 es un estado final asociado al
operador DIV, es decir, a la división.
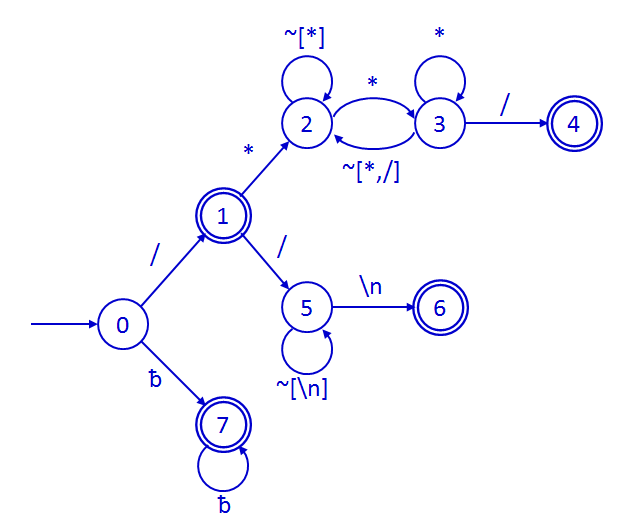
Los identificadores del lenguaje comienzan por una
letra o un subrayado y pueden ir seguidos de cualquier número de letras,
dígitos y subrayados. Las palabras clave del lenguaje son reconocidas en
primer lugar como identificadores. El método
getToken(int,String,int,int) estudia en el caso de los identificadores
(estado 8) si el lexema corresponde a una palabra clave, devolviendo en
este caso el componente léxico correspondiente y en caso contrario un
componente de tipo identificador.
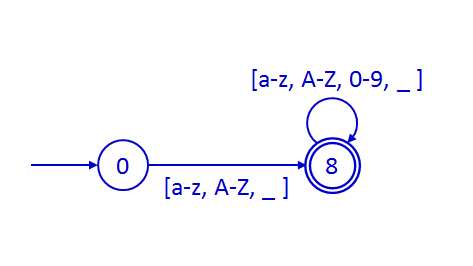
Los literales de tipo entero pueden definirse en cuatro
formatos: decimal, octal, hexadecimal y binario. El formato decimal debe comenzar
con un dígito del 1 al 9, seguido de dígitos del 0 al 9. El formato octal
comienza con un dígito 0 seguido de dígitos del 0 al 7. El formato
hexadecimal comienza con "0x" o "0X" seguido de dígitos hexadecimales
(0-9, a-f, A-F). El formato binario comienza con "0b" o "0B" seguido
de dígitos binarios (0 o 1).
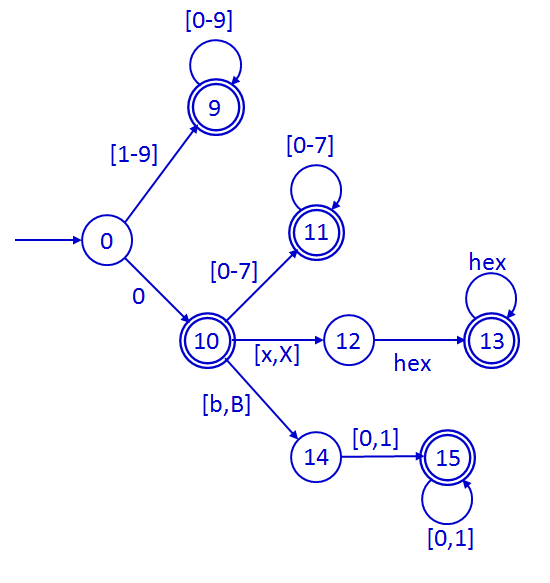
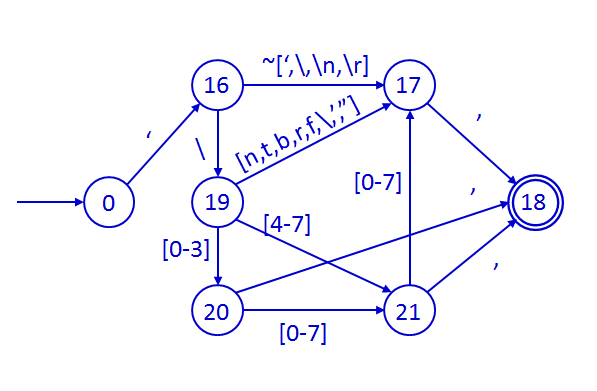
- Literales de tipo carácter
Los literales de tipo carácter comienzan y terminan con
una comilla simple. Admiten tres formatos: los caracteres imprimibles se
indican entre comillas simples. Los caracteres no imprimibles se indican
mediante un carácter de escape: \n denota un salto de línea; \r denota un
retorno de carro; \t denota un tabulador, \\ denota una barra invertida,
\' denota una comilla simple, \" denota una comilla doble. Otro formato
aceptado consiste en escribir el formato octal del código ASCII del
carácter deseado, precedido del carácter de escape. A continuación se
muestra la parte del autómata asociada a los literales de tipo carácter.
Los separadores del lenguaje son los paréntesis, las
llaves, la coma, el punto y el punto y coma.
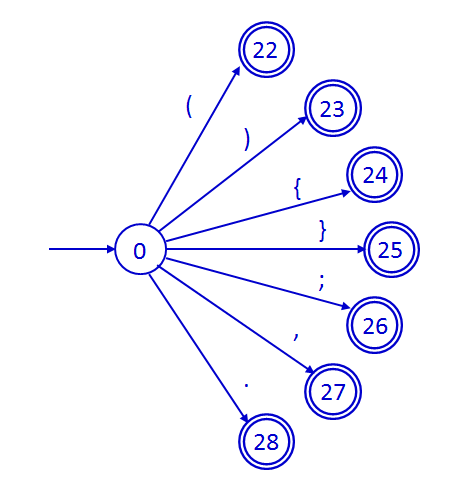
- Comparadores y operadores lógicos
A continuación se muestra la parte del autómata asociada a los
comparadores del lenguaje (igualdad, desigualdad, menor, mayor, etc.) y a
los operadores lógicos (AND y OR).
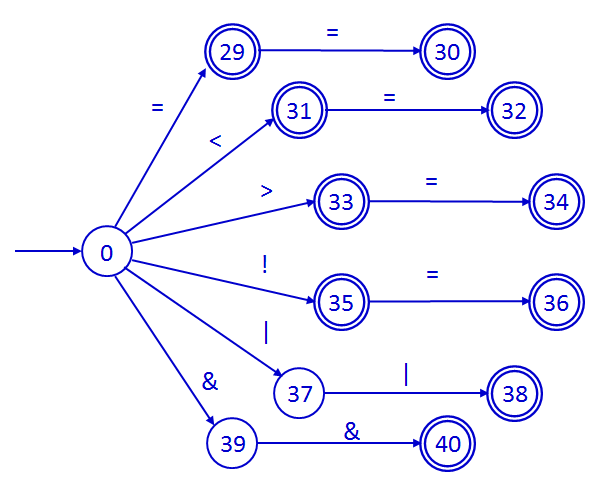
Los operadores aritméticos incluidos en el lenguaje son
la suma, la resta, la multiplicación, la división y el módulo. El operador
de división se reconoce en el estado 1. El resto se reconoce en el
siguiente trozo del autómata.
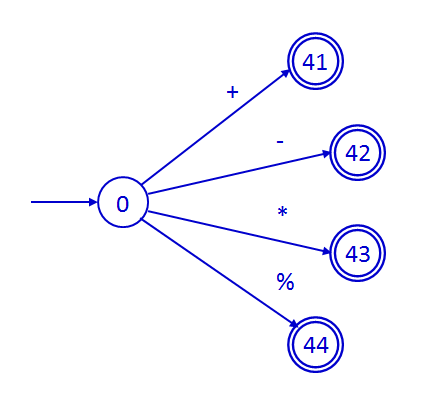
|
|
EL COMPILADOR DE TINTO
|
|
La clase principal del compilador de Tinto se encuentra en el paquete
tinto y se denomina TintoCompiler. Esta clase contiene el
método main() que lanza la aplicación. En esta práctica, el funcionamiento
del compilador se limita a explorar el directorio de trabajo, abrir
el fichero 'Main.tinto' y ejecutar el analizador léxico sobre él.
En caso de error, el compilador genera el archivo 'TintocErrors.txt'
con la descripción del error detectado. Si el análisis léxico es correcto
el compilador genera el archivo 'TintocOutput.txt' con el listado
de los tokens generados.
El compilador de Tinto consiste en un archivo denominado 'tintoc.jar'.
Este archivo se puede ejecutar con el comando 'java -jar tintoc.jar'
o simplemente pulsando sobre el archivo (el sistema operativo tiene asociado
el comando 'java -jar' a los archivos con extensión '.jar').
Para generar el fichero 'tintoc.jar' se utiliza la herramienta
'ANT' que está incorporada al entorno Eclipse. Para ello se ejecuta
el fichero de configuración de ANT ('antbuild.xml') por medio de
la opción 'Run As -> Ant Build'.
El código de la práctica incluye un directorio llamado examples
que contiene un ejemplo de una aplicación programada en Tinto. Para
probar el compilador hay que copiar el archivo 'tintoc.jar' en
el directorio de la aplicación y ejecutarlo.
|
|
