|
Procesadores de Lenguajes
Curso 2024/2025
|
Trabajo |
|
Generador de Analizadores Sintácticos Ascendentes |
|
OBJETIVOS |
-
El objetivo de este trabajo es desarrollar "a mano" una aplicación que tome como
entrada la descripción de una gramática en notación BNF, calcule la tabla de
desplazamiento/reducción por medio del algoritmo SLR y genere como salida los
ficheros "TokenConstants.java", "SymbolConstants.java" y "Parser.java" que desarrollen
el Analizador Sintáctico Ascendente para la gramática de entrada.
|
|
ESPECIFICACIÓN LÉXICA |
La especificación léxica de las gramáticas en notación BNF están formadas por las
siguientes categorías:
| Especificación |
Expresión
regular |
| blanco |
( " " | "\r" | "\n" | "\t" ) |
| comentario |
"/*" ( ("*")* ~["*", "/"] | "/" )* ("*")+ "/" |
| NOTERMINAL |
["_","a"-"z","A"-"z"] (
["_","a"-"z","A"-"Z","0"-"9"] )* |
| TERMIINAL |
"<" ["_","a"-"z","A"-"z"] (
["_","a"-"z","A"-"Z","0"-"9"] )* ">" |
| EQ |
"::=" |
| BAR |
"|" |
| SEMICOLON |
";" |
La categoría NOTERMINAL está asociada a identificadores y se utiliza para
referenciar a los símbolos no terminales de la gramática. La categoría TERMINAL se refiere
a los símbolos terminales de la gramática, que se escriben como identificadores
entre los signos menor ("<") y mayor (">"). La categoría EQ se refiere a la
flecha que separa las partes izquierda y derecha de una regla. La categoría BAR
reconoce el separador entre diferentes reglas de un mismo símbolo no terminal.
La categoría SEMICOLON reconoce el punto y coma que se utiliza como finalizador
de las reglas de un símbolo no terminal.
Los blancos se refieren a espacios, tabuladores y saltos de línea y corresponden
a componentes léxicos que deben ser filtrados. Los comentarios, que también deben ser filtrados, son iguales que los
comentarios multilínea de C.
|
|
ESPECIFICACIÓN SINTÁCTICA |
La especificación sintáctica de las
gramáticas es la siguiente:
-
Gramatica ::= ( Definicion )*
-
Definicion ::=
NOTERMINAL EQ ListaReglas
SEMICOLON
-
ListaReglas ::= Regla ( BAR Regla
)*
-
Regla ::= ( NOTERMINAL |
TERMINAL )*
Una
gramática es un conjunto de definiciones. Cada definición describe el conjunto
de reglas asociadas a un símbolo no terminal de la gramática. Estas definiciones
están formadas por el identificador del símbolo no terminal (NOTERMINAL),
seguido del símbolo EQ, seguido de las reglas asociadas a ese símbolo no
terminal y terminado en SEMICOLON (es decir, un punto y coma). La lista de
reglas está formada por reglas separadas por BAR (es, decir, una barra). Las
reglas están formadas por una secuencia de símbolos terminales o no terminales.
Para representar una regla lambda se utiliza una secuencia vacía.
|
|
EJEMPLO DE FUNCIONAMIENTO |
El siguiente texto describe un ejemplo de entrada correcta para la aplicación a
desarrollar. Se trata de la descripción de las expresiones aritméticas formadas
por sumas, restas, multiplicaciones y divisiones de números y llamadas a
funciones.
/* Definición de una expresión aritmética como una suma o resta de términos */
Expr ::= Term
| Expr <PLUS> Term
| Expr <MINUS> Term
;
/* Los términos son productos o divisiones de factores */
Term ::= Factor
| Term <PROD> Factor
| Term <DIV> Factor
;
/* Los factores son constantes, expresiones entre paréntesis o llamadas a funciones */
Factor ::= <NUM>
| <LPAREN> Expr <RPAREN>
| <IDENTIFIER> <LPAREN> Args <RPAREN>
;
/* Las reglas lambda se crean con secuencias vacías, como la segunda línea de esta definición */
Args ::= ArgumentList
|
;
/* Los argumentos son una lista de expresiones separadas por coma */
ArgumentList ::= Expr
| ArgumentList <COMMA> Expr
;
|
El fichero "TokenConstants.java" a generar debe describir una interfaz con los
valores de los símbolos terminales utilizados en la gramática. El primero de los
símbolos terminales a definir es siempre EOF, que debe tener el valor 0. A
continuación se definirán los símbolos terminales de la gramática en el orden en
el que aparezcan y con valores correlativos. El contenido de este fichero para
el ejemplo planteado debe ser el siguiente:
public interface TokenConstants {
public int EOF = 0;
public int PLUS = 1;
public int MINUS = 2;
public int PROD = 3;
public int DIV = 4;
public int NUM = 5;
public int LPAREN = 6;
public int RPAREN = 7;
public int IDENTIFIER = 8;
public int COMMA = 9;
}
|
El fichero "SymbolConstants.java" a generar debe describir una interfaz con los
valores de los símolos no terminales utilizados en la gramática. El primero de los
símbolos no terminales a definir debe ser el símbolo inicial, que debe tener el valor 0. A
continuación se definirán los símbolos no terminales de la gramática en el orden en
el que aparezcan y con valores correlativos. El contenido de este fichero para
el ejemplo planteado debe ser el siguiente:
public interface SymbolConstants {
public int Expr = 0;
public int Term = 1;
public int Factor = 2;
public int Args= 3;
public int ArgumentList= 4;
}
|
El análisis SLR en este ejemplo da como resultado la siguiente tabla de
desplazamiento/reducción:
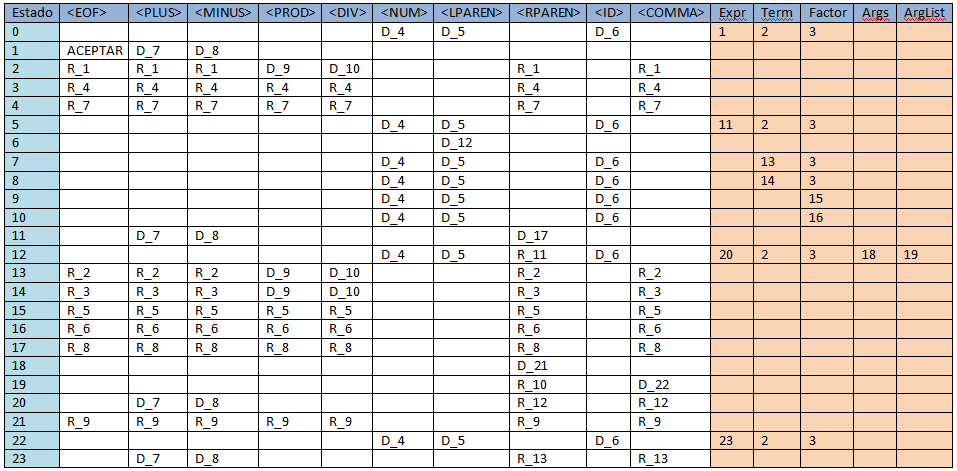
El código de la clase "Parser.java" a generar corresponde al modelo
explicado en la práctica 7 de la asignatura. Se asume que
los ficheros "ActionElement.java", "SintaxException.java" y "SLRParser.java" son
los mismos que los incluidos en dicha práctica y que han sido generados por otro
medio. A continuación se presenta un fragmento del contenido del fichero
"Parser.java" a generar para este ejemplo:
public class Parser extends SLRParser implements TokenConstants, SymbolConstants {
public Parser() {
initRules();
initActionTable();
initGotoTable();
}
private void initRules() {
int[][] initRule = {
{ 0, 0 } ,
{ Expr, 1 },
{ Expr, 3 },
{ Expr, 3 },
{ Term, 1 },
{ Term, 3 },
{ Term, 3 },
{ Factor, 1 },
{ Factor, 3 },
{ Factor, 4 },
{ Args, 1 },
{ Args, 0 },
{ ArgumentList, 1 },
{ ArgumentList, 3 }
};
this.rule = initRule;
}
private void initActionTable() {
actionTable = new ActionElement[24][10];
actionTable[0][NUM] = new ActionElement(ActionElement.SHIFT,4);
actionTable[0][LPAREN] = new ActionElement(ActionElement.SHIFT,5);
actionTable[0][IDENTIFIER] = new ActionElement(ActionElement.SHIFT,6);
actionTable[1][EOF] = new ActionElement(ActionElement.ACCEPT,0);
actionTable[1][PLUS] = new ActionElement(ActionElement.SHIFT,7);
actionTable[1][MINUS] = new ActionElement(ActionElement.SHIFT,8);
...
}
private void initGotoTable() {
gotoTable = new int[24][5];
gotoTable[0][Expr] = 1;
gotoTable[0][Term] = 2;
gotoTable[0][Factor] = 3;
...
}
}
|
El siguiente enlace contiene el código completo de los ficheros a generar, así como el código
de las clases auxiliares necesarias para completar completar el analizador (ActionElement,
SintaxException, SLRParser y Token) y las que desarrollan el analizador léxico en este caso
(BufferedCharStream, ExprLexer, Lexer y LexicalError).
|
|
DESARROLLO DEL TRABAJO |
Los pasos a realizar en el desarrollo del trabajo son los siguientes:
- Desarrollar el analizador léxico correspondiente a la especificación léxica
indicada en el trabajo. Se recomienda hacer uso de las clases auxiliares
explicadas en la práctica 3 de la asignatura.
- Generar una gramática LL(1) equivalente a la especificación sintáctica indicada y calcular los conjuntos de predicción
de la gramática.
- Desarrollar el analizador sintáctico siguiendo la estructura
explicada en el tema 4 de la asignatura.
- Definir las clases necesarias para describir el Árbol de
Sintaxis Abstracta a utilizar en el trabajo.
- Ampliar el analizador sintáctico para considerar la semántica, es decir,
construir un analizador semántico que tome como entrada la descripción en modo
texto de una Gramática BNF y genere como salida una estructura de datos que
represente la Gramática BNF reconocida.
- Programar el algoritmo SLR de cálculo de la tabla de desplazamiento/reducción de
una gramática BNF.
- Programar el generador de código que cree los ficheros "TokenConstants.java" y
"SymbolConstants.java" a partir de los símbolos terminales y no terminales de la
gramática
- Programar el generador de código que cree el fichero "Parser.java" a partir de
la tabla de desplazamiento/reducción.
- Realizar un conjunto de pruebas sobre la aplicación.
|
|
DOCUMENTACIÓN A ENTREGAR |
Se entregará el código desarrollado en formato electrónico (debidamente
compilado) así como una memoria descriptiva del trabajo. La memoria a
entregar debe incluir los siguientes puntos:
- Autómata Finito Determinista en el que se basa el analizador léxico.
- Código de la clase que desarrolla el analizador léxico.
- Gramática BNF en la que se basa el analizador sintáctico.
- Conjuntos de predicción de dicha gramática.
- Código de la clase que desarrolla el analizador
sintáctico/semántico.
- Código de las clases que desarrollan el Árbol de Sintaxis Abstracta.
- Código de la clase que desarrolle el algoritmo SLR y explicación de su funcionamiento.
- Código de las clases que describen la tabla de desplazamiento/reducción generada
por el algoritmo SLR.
- Código de las clases que desarrollen la generación de los ficheros
"TokenConstants.java", "SymbolConstants.java" y "Parser.java" y
explicación de su funcionamiento.
- Pruebas del funcionamiento de la aplicación.
|
|
PLAZO DE ENTREGA |
- La fecha límite de entrega para su evaluación en la primera
convocatoria será el viernes 20 de junio de 2025.
- La fecha límite de entrega para su evaluación en la segunda convocatoria será el viernes
19 de julio de 2025.
|
|
