
Grado en Ingeniería Informática
Procesadores de Lenguajes
Curso 2022/2023
| Práctica 1 |
| Características generales del lenguaje Tinto |
|
Objetivos |
|
|
Código de la práctica |
|
|
Características generales del lenguaje de programación Tinto |
|
|
Tinto es un lenguaje de programación imperativo orientado a procesos (tipo C). El objetivo de Tinto es definir un lenguaje de programación muy simple que sirva de apoyo a la docencia de la asignatura de Procesadores de Lenguaje. En cada uno de los aspectos de diseño de Tinto (especificación léxica, sintáctica y semántica, tipos de datos, instrucciones, etc.) se ha optado por simplificar el lenguaje de forma que sea posible afrontar el desarrollo de un compilador tanto de forma manual como con la ayuda de herramientas. De esta forma, el lenguaje Tinto servirá como ejemplo en las sesiones prácticas en las que se explica cómo desarrollar un analizador léxico, un analizador sintáctico, etcétera. A continuación se muestra un ejemplo del contenido de un fichero fuente descrito en lenguaje Tinto:
Algunas de las características de Tinto son las siguientes:
|
|
Proceso de compilación y ejecución de programas en Tinto |
|
|
El compilador de Tinto se encuentra en el archivo tintoc.jar. Para realizar un proceso de compilación se debe ejecutar este archivo desde una línea de comandos:
El objetivo del compilador es compilar el archivo Main.tinto que debe contener la función Main() que marca el comienzo de la aplicación programada. A partir de esta biblioteca se analizan y compilan el resto de bibliotecas importadas. Por defecto el directorio de trabajo es desde aquel en el que se ejecuta el comando de compilación, pero se puede modificar por medio de las opciones. Por defecto las bibliotecas importadas deben encontrarse en el directorio de trabajo pero se pueden configurar otros directorios de búsqueda por medio de la opción -I. El resultado de la compilación es un archivo con extensión ".s" con el código ensamblador que desarrolla la aplicación programada. Por defecto, el archivo generado como salida se denomina "Application.s" pero este nombre se puede modificar por medio de la opción -o. Por medio de la opción -v se le puede indicar al compilador que genere archivos con la descripción del código intermedio en modo texto. Las opciones que admite el compilador son las siguientes:
La distribución del compilador de Tinto contiene algunos ejemplos y un directorio llamado Utils que incluye una biblioteca llamada Console. Esta biblioteca contiene varios métodos de presentación de información en la consola. Para utilizar correctamente esta biblioteca es aconsejable añadir el directorio Utils como directorio de búsqueda por medio de la opción -I. El resultado de la compilación es un fichero escrito en ensamblador del procesador MIPS. Para ejecutar este código se utiliza el simulador Qt-Spim.
|
|
Características del procesador MIPS |
|
MIPS (Microprocessor without Interlocked Pipeline Stages) es el nombre de una familia de procesadores RISC desarrollados por MIPS Technologies. La empresa concede licencias a otros fabricantes para integrar la arquitectura MIPS en sus productos (por ejemplo, CISCO, SGI, Toshiba, Sony, ...). La arquitectura MIPS es la base de los procesadores de muchos routers de CISCO, de las estaciones de trabajo de SGI, de las videoconsolas Nintendo 64, PlayStation, PlayStation 2, PlayStation Portable, de las impresoras de HP, etc. Algunas de las características más interesantes de la arquitectura MIPS son las siguientes:
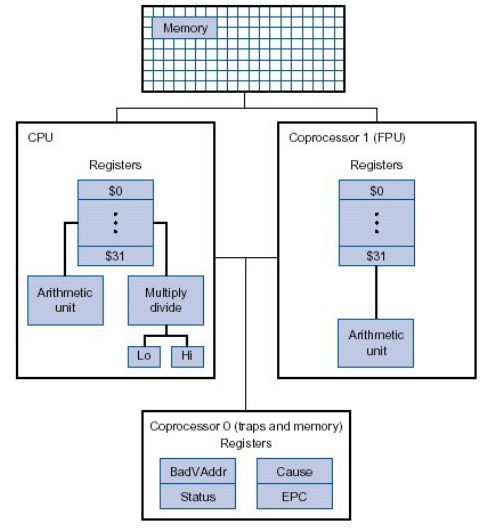
La arquitectura cuenta con una unidad de propósito generar formada por 32 registros de 32 bits ($0 a $31) y una unidad de coma flotante con 32 registros de 32 bits ($f0 a $f31) que se pueden utilizar como 16 registros de 64 bits para almacenar datos en formato double.
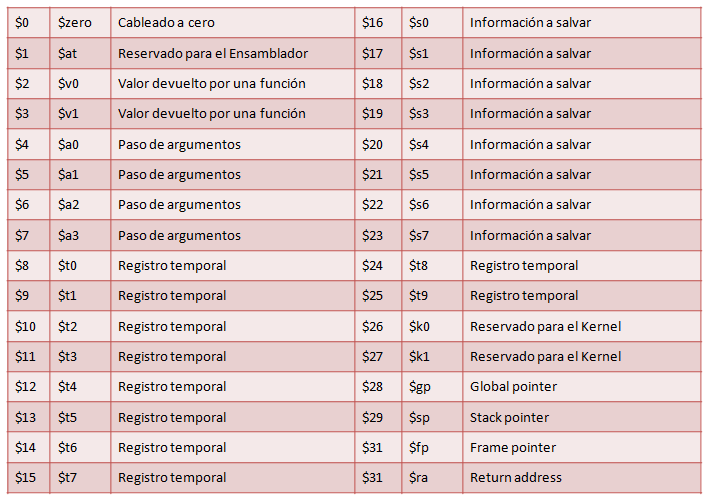
Los registros de propósito general pueden usarse libremente en las instrucciones, aunque hay que tener en cuenta que el registro $0 está cableado a 0 y que el registro $31 almacena la dirección de retorno cuando se ejecuta una instrucción JAL (jump and link). El resto de registros se puede utilizar libremente aunque se recomienda seguir un convenio de uso de los registros que indica el tipo de dato que se debe almacenar en cada registro. Este convenio incluye utilizar una serie de alias para referirse a los registros. La siguiente tabla describe el convenio de uso de los registros de MIPS.
El conjunto de instrucciones es sencillo y potente (Instrucciones CPU) (Instrucciones FPU) (Tabla resumen). La descripción completa de cada instrucción se encuentra aquí.
|
|
El simulador Qt-Spim |
|
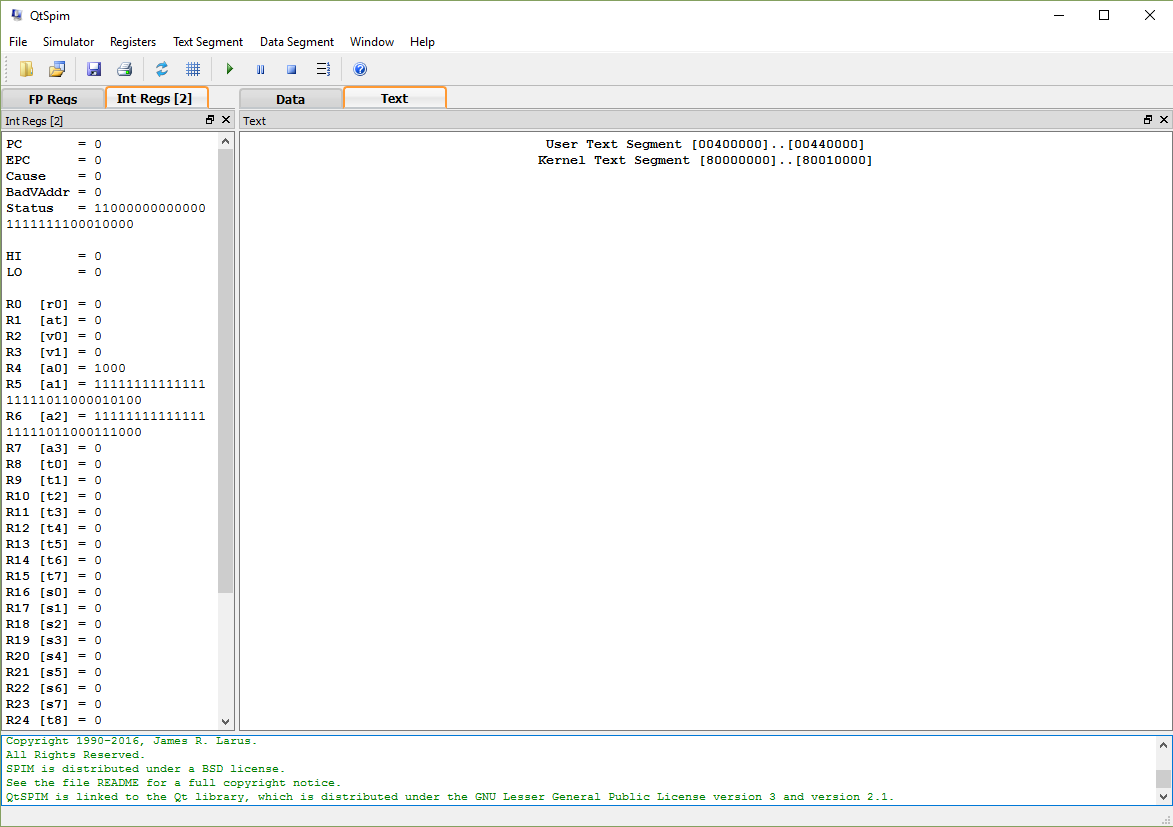
SPIM es un simulador que ejecuta programas descritos en ensamblador de MIPS32. La herramienta ha sido programada por James Larus y se distribuye libremente. La versión más reciente se denomina QT-SPIM y se puede descargar desde la página oficial. El simulador desarrolla un conjunto mínimo de llamadas al sistema que permiten acceder a una consola y acceder a ficheros. La tabla de llamadas al sistema es ésta. La ventana principal de Qt-Spim muestra tres paneles: el panel de la iquierda muestra el contenido de los registros del procesador, el panel de la derecha muestra el contenido de la memoria y el panel inferior se utiliza para mostrar mensajes. El panel de registros tiene dos pestañas que permiten seleccionar entre los registros de propósito general (GPR) y los registros de la unidad de coma flotante (FPR). El panel de memoria tiene también dos pestañas que permiten mostrar el segmento de texto (que contiene las instrucciones del programa a ejecutar) y el segmento de datos (que contiene la pila y la memoria estática y dinámica).
Para ejecutar un programa (el fichero Application.s, en nuestro caso) en primer lugar hay que cargarlo (Opción File->Load file). A continuación se puede ejecutar completamente (F5) o paso a paso (F10). También es posible establecer puntos de parada (breakpoints) y ejecutar el programa a saltos. El proceso de ejecución se configura por medio de la opción (Simulator -> Settings). En nuestro caso, las opciones "Enable Delayed Branches" y "Enable Delayed Loads" deben estar marcadas para simular el procesador de forma realista. La opción "Accept Pseudo Instructions" tambien debe estar marcadas, ya que el ensamblador generado por el compilador de Tinto utiliza algunas pseudo-instrucciones. Es importante desmarcar la opción "Load Exception Handler" ya que nuestro fichero Application.s ya contiene el código de las excepciones.
El simulador contiene una consola en la que se pueden mostrar e introducir datos.
|

|
Ejercicios |
|